 View All
View AllHanzi Universe




Can an algorithm recognise similar Chinese characters?
The short answer is yes. The Structural Similarity Index scores paired with force directed graph have done an amazing job in organising many similar looking Chinese characters into clusters.

In the image above, we see a cluster of characters with 口 radical on the left and 目 radical on the right. While it’s not obvious how the the characters on the two sides are visually related, some interesting observations can be made. For example, the characters 孤 (gū) and 弧 (hú), found in the centre top:
- The proximity of these characters suggests very high resemblance, and they are!
- These characters have different consonants, ‘g’ and ‘h’, but share the same vowel ‘u’
- The vowel ‘u’ is pronounced with different tones: ū tone 1 and ú tone 2.
Hidden patterns within the complexity

For all characters that are pronounced ‘han’, you’ll see instances distributed across the whole map. The fact that 汉 (hàn) looks nothing like 焊 (hàn), even though they sound exactly the same, is an indication of the complexity of the Chinese language. Upon close examination, you’ll notice many of these ‘han’ characters possess the same phonetic component (right part of the character), like 焊, 悍, and 捍.
Where the algorithms failed
Our method of clustering by structural similarity seems to have limitations when dealing with a subset of characters that are very simple (less number of strokes to write), or very complex (lots of strokes). These characters get pushed into a large clump with no apparent relationship to each other.

View the Hanzi Universe star map
Related projects and articles
-
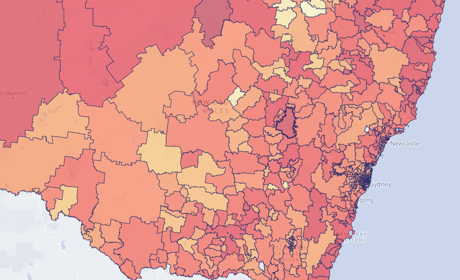
Occupational Risk due to COVID-19 in NSW
Article
-
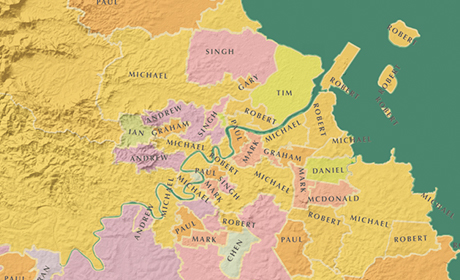
Business empires in Australia
Article
-
Census Data Explorer
SBS
-
State of Play
The Australian